






One of the cornerstones of successful software product development is the speed with which you can implement ideas and release them to market. A well-structured continuous deployment process plays a pivotal role in achieving this agility while reducing the stress often associated with release days.
At Focalworks, we’ve navigated diverse contexts—ranging from aiding early-stage startups in transforming ideas into market-ready products to helping multinational companies re-architect and scale their software. The right solution varies depending on the context, and we’ve honed our approach accordingly.
In our experience, startups typically require a nimble environment that facilitates rapid development, deployment, and validation. As a technology partner, we understand that alongside this velocity, maintaining code quality and security is paramount.
In this article, I’ll delve into how we transitioned from a manual deployment process to a fully automated deployment on Medstack for one of our favourite client partners—Trualta Care Network, a startup in the healthcare space.
The Backstory
Five years ago, we embarked on developing a custom Laravel solution for Trualta to build a platform that empowers caregivers to enhance their skills. The immediate goal was to get the product into the hands of a few family caregivers and gather early feedback. The plan was to foster organic adoption and growth. Initially, we managed the entire setup on a single virtual server, deploying everything manually.
The product’s initial reception was overwhelmingly positive, quickly gaining traction among caregiver support groups and organisations. Given the specific needs expressed by various organisations, we made an early decision to create separate codebases for some of these early clients, managing separate deployments.
This approach worked for about a year.
As demand for new deployments surged, turnaround times became critical, and the risk of manual oversights became evident. To automate code updates and multiple deployments, we wrote Bash scripts to execute the necessary Linux shell commands.
Over the next couple of years, the product evolved rapidly, driven by interesting feature requests from various clients. However, the time spent on pushing code updates for each client deployment became unsustainable. Moreover, with prospective clients such as insurance companies and government agencies, it became essential to ensure compliance with standards like HIPAA. This objective led us to transition our hosting to Medstack.
Medstack provides a platform with built-in privacy and security protocols tailored to healthcare industry expectations, including encryption, certificate and key management, backups, monitoring, and logging. Working with their team was a great experience, offering us a chance to explore a new platform and its capabilities.
Transitioning to Automation
As part of our ongoing journey toward achieving the highest possible data privacy and protection, we aimed to implement the best access control and deployment automation processes. We migrated the entire application codebase to a multi-tenant architecture—a topic I’ll discuss in a separate article. Leveraging Medstack’s Docker-based deployment and strong API support, we automated the deployment process so that the development team had no visibility into user data.
The Current Continuous Deployment Process
Let me walk you through our current continuous deployment process, established through our re-engineering initiative, to deploy incremental code changes.
1. Building a Docker Image
We start with a Docker image. As avid GitLab users, we opted to use GitLab pipelines and runners to build our Docker images. We create a tag on GitLab, which triggers a GitLab pipeline. This pipeline runs a code scan for secret detection and then begins the image build process. Once completed, we receive a notification on our Zulip chat application, which we use for internal communication. (By the way, Zulip is a fantastic open-source alternative to Slack, and you can host it on your infrastructure.)
2. Creating a Release Tag on GitLab
First, we create a release tag on GitLab. This can either be a beta release, meaning the deployment will be done on the staging server for review, or a production release, triggering the pipeline responsible for deploying the code to the production server.

We follow semantic versioning, where we increment the Y part when a new feature is added. Any bug fixing or patches result in incrementing the Z part.
3. Pipeline Execution
The tag creation triggers the pipeline. Right now, we have two stages in our pipeline which you can see in the screenshot below.
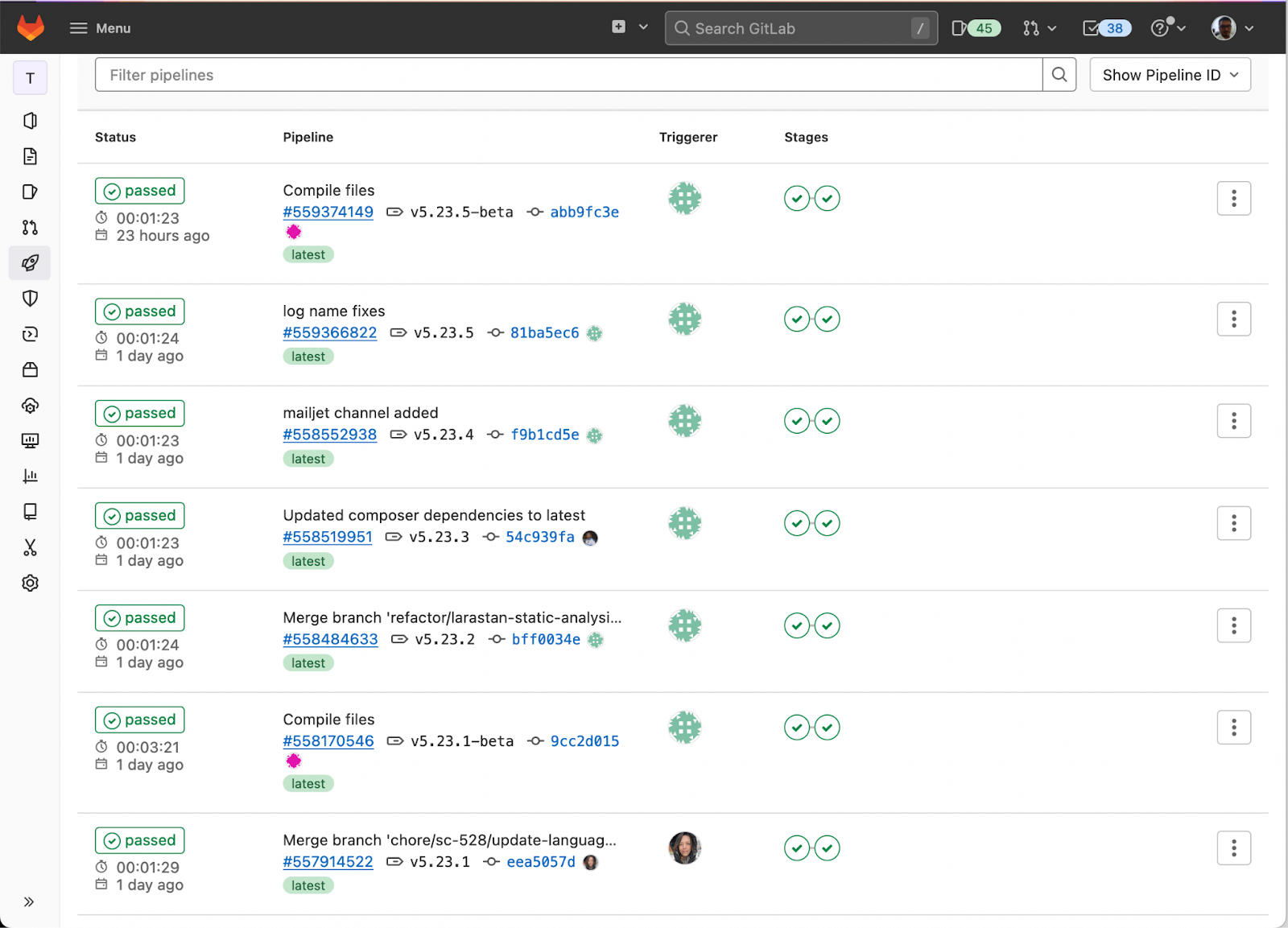
Once the pipeline is complete, we have configured Gitlab to send a notification to Zulip. A typical success notification looks like this:

4. Pushing the Docker Image
After this, the developer waits for the optimal time to push the new Docker image using the Medstack API. We maintain a shell script that makes the necessary CURL call to the API and then performs a routine check on each client’s instance to ensure that the containers are up and running with the latest Docker image version. Below is a flow diagram of the deployment process.
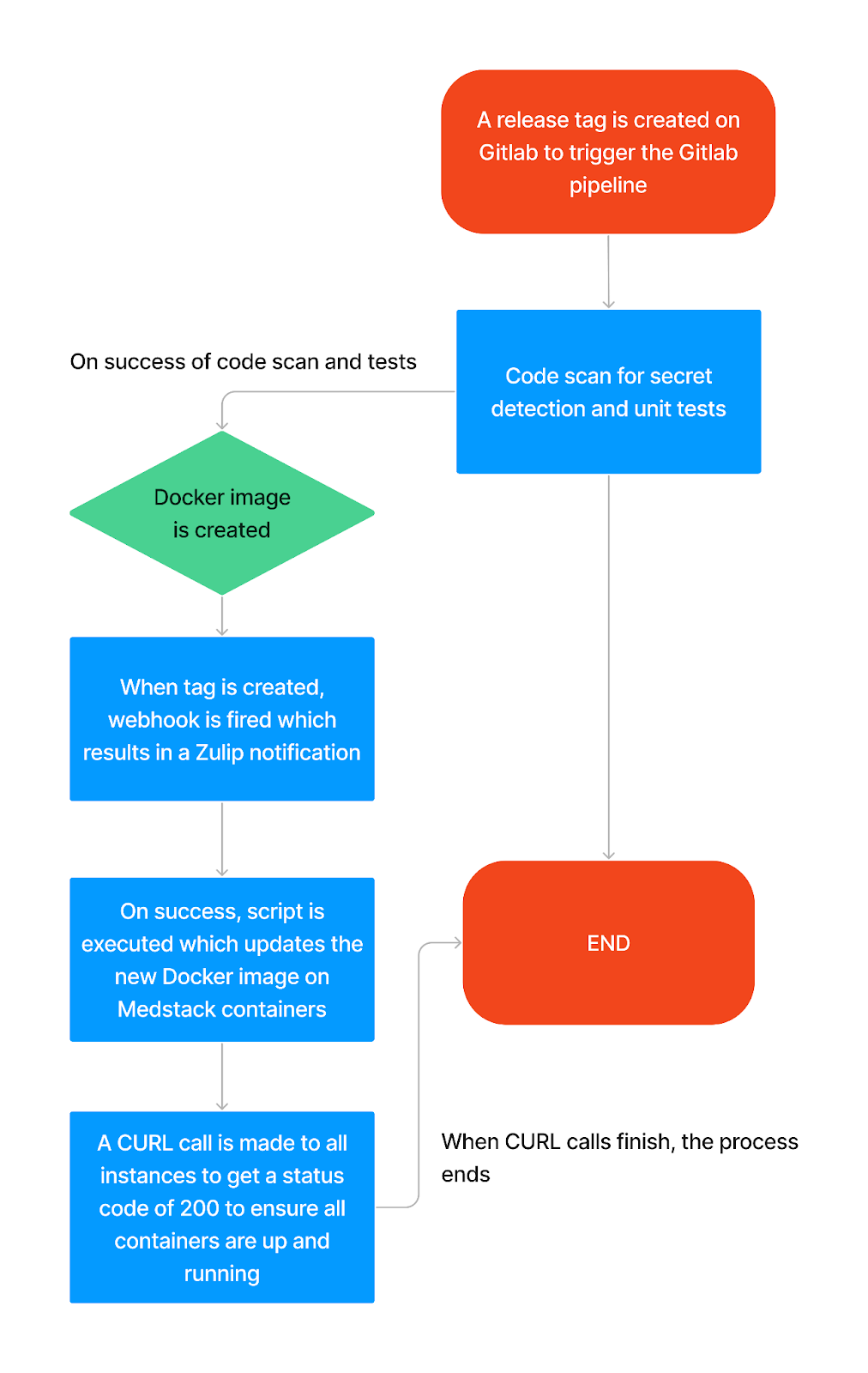
5. Handling Failures
The deployment process is automated, and on a good day, everything works smoothly. However, issues can arise—this is inevitable when humans are involved. If the build process fails, Zulip sends a notification informing us of the failure. It’s then a manual process to diagnose the issue. For instance, recently, our pipelines began failing due to full disk space. We wrote a script to remove unused images, keeping disk usage to a minimum.
6. Controlled Access and Tagging
Now, building and updating a server can be done by simply creating a tag on GitLab. There’s no need to give server-level access to developers, and we also control who can deploy code since not everyone has permission to create a tag on GitLab. With this level of automation, deployment of code to staging or production environments has become so simple that developers can push releases daily without worrying about breaking something. This has significantly reduced turnaround time.
Conclusion
By implementing a robust and automated continuous deployment process, we’ve created an environment where the entire team, including developers, feels empowered to innovate, removing any points of friction. This approach has significantly enhanced the efficiency of the software development process for the business owner.
Photo by Alesia Kazantceva on Unsplash
Written by: Amitav Roy
Edited by: Tanmoy Palit
Table of Contents


