






In the fast-paced world of software development, navigating complex tasks such as migrating an entire AWS infrastructure from one region to another with minimum downtime requires both technical expertise and meticulous planning. In this blog post, I’ll be sharing insights into our team’s journey as we undertook the formidable challenge of relocating our client’s AWS infrastructure from Canada to the US region with zero downtime.
TL;DR
We migrated entire AWS services for one of our client’s multi-tenant SaaS applications to address data privacy issues from Canada to the US region with zero downtime. If you have similar requirements, get in touch with us.
The need
Several essential elements of our client’s multi-tenant SaaS application needed to be transferred from AWS’s Canada region to the US region. Close to 100 tenants were sending data to the AWS infrastructure, so it was crucial to adhere to SLAs and have no data loss.
What did the infrastructure look like?
It’s important to understand the inventory we were looking at before getting into the specifics of the migration procedure. As a first step, it was crucial for us to document all the many services we were currently using. Next, we ascertained whether the services could tolerate downtime—which would make them technically simple to move—versus those that are on a critical path, where a little hiccup could result in data loss.
This is what our infrastructure looked like:

As you can see, our Lambda Functions get data from multiple sources in the form of webhooks. So, the migration of different services had different levels of complexity. Some elements such as the Analytics app and the SQS were easy to migrate, while services such as Lambda and the RDS were tricky.
In terms of the inventory we had to move, here’s the list we created to have a clear picture of how many services we were using and what sequence to follow to manage dependencies:
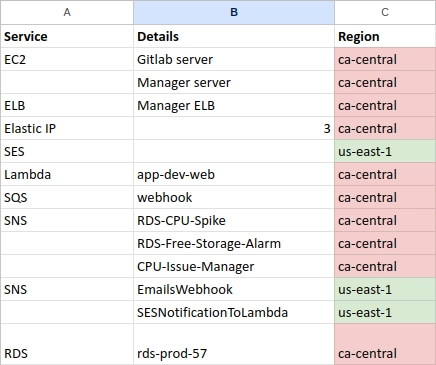
With the inventory list in front of us, we were doing individual POCs to ascertain how the migration of certain services could be done in isolation and without disrupting anything on the main client infrastructure.
What were the challenges?
The RDS migration
We had to update our RDS MySQL version at the same time that we decided to migrate. We were using an older version of MySQL, and the upgrade directive arrived just as we were preparing to move. We were running on 5.6 and we were upgrading to 8.0. We saw this as a challenge, but the upgrade was beneficial for us.
We employed the replication process, so a read replica of our RDS instance was generated. The version of the newly created read-only database was then upgraded to the latest iteration. This method allowed us to proactively identify errors that could potentially arise during the migration process. We did encounter a few minor issues, but the overall migration proceeded without significant disruptions.
Notably, AWS provides a script designed to scrutinise and identify compatibility issues, concurrently generating a comprehensive log file documenting any encountered problems. One of the most common problems was the use of an obsolete data type. (For a detailed list of checks, refer to this page of AWS docs.) This operational feature significantly eased the troubleshooting process, ensuring a swift and efficient resolution to any identified issues.
Thanks to the replication procedure, we had the database servers in both regions in sync. We did anticipate the possibility of data loss because DNS resolution time would be affected during the DNS switchover. To minimise the possibility of downtime and data loss, we created a script that could sync missing entries from the old database to the new. As it happened, we achieved zero downtime with no data loss.
The Lambda Function migration
Our API gateway URL was called directly by our application and other third-party services; a new setup would mean we would have to change all those URLs. Having a domain or subdomain makes these changes easier because all that needs to be done is to update the subdomain’s CNAME to point to the new API gateway. This usually requires a few seconds to take effect, so for a truly zero downtime scenario, we would replace the service on the old IP with a reverse proxy to the new service on the new IP so that irrespective of name resolution all requests would be serviced from the new IP the instant the reverse proxy activated. However we did have a clear maintenance window when the application had no active users, so in the interest of saving costs to the client we went ahead with simply switching over the DNS entry during that window.
So to begin with, we changed the URL in our main application and other services to use the new subdomain. Once that was done, we initiated the process of migrating the Lambda and API gateway to the new region. We used the serverless framework here. The Lambda Functions run Laravel code, which is deployed using Bref. The migration of this part of the application to the new region was very smooth; Bref creates a CloudFormation template and everything is automated.
I am a big fan of automated deployment. It makes me feel much more confident about the deployment process when it is repeatable. We are already using CI/CD pipelines for the entire deployment for this client. You can read more about this here: Continuous Deployment with Automation with HIPAA on Medstack.
SQS, ACM, ELB, SES, and SNS migration
These services were not on a very critical path. The plan was to migrate them—essentially, create a copy and have them prepared. Importantly, we had to very carefully copy all the configurations to the new region and validate them manually. Ideally, a CloudFormation template would have helped a lot.
Once the entire infrastructure is operational in the new region, these services will be activated—and we will cease the services running in the Canada region.
The SQS queue is being used by the Lambda Functions and the Manager application running on our EC2 instance to process the webhooks. We had created the entire infrastructure and kept it running because we knew nothing new would come by until we changed the DNS.
Creating a new certificate using ACM was also straightforward. The certificate from one region is not available to the ELB in another region, so we created that as well before the day of the migration.
We utilised SES primarily for sending emails. SNS topics were established to capture events from SES concerning delivery, opens, and clicks. These webhooks were also consumed by the new Lambda Functions, which made testing them uncomplicated.
EC2 instance migrations
With a CI/CD pipeline setup, we were really not very concerned about these migrations either. The server only required Docker to run the containers and Nginx to configure the proxy. We just changed the IP of the server to which the pipeline would connect—and that’s it!
However, within the AWS ecosystem, the migration can be very simple even if you are not using a Dockerised system. You can always create an AMI and then use that AMI to spin up a new instance.
In conclusion, migrating our AWS infrastructure from Canada to the US presented challenges but ultimately proved to be a successful journey. By meticulously planning, leveraging AWS tools, and adopting a methodical approach, we were able to overcome obstacles and ensure a smooth transition. This experience has further solidified the importance of a comprehensive inventory, thorough testing, and leveraging automation whenever possible.
I hope this blog post provides valuable insights for anyone considering a similar migration within the AWS ecosystem. If you have similar requirements, feel free to reach out to us.
Table of Contents

